前言
在平时的 Coding 过程中,我们还是需要一定的 Git 操作的能力的。但是总还是存在一些场景自己突然想不起来,某个场景,应该使用什么 Git 命令可以满足自己的诉求,这个时候又需要打开 Google / Baidu,各种搜索一番,与其把时间消磨在这一次次的重复工作中,倒不如好好研究一下我们常用的命令的玩法。在这里,本文也将提供一系列的案例,为大家介绍这些常用的 Git 的体系和命令的应用场景以及大体的使用方式。
当然,除了我们需要了解 Git 的命令使用方式之外,我们也应该来了解下 Git 是的整个体系结构是怎么样的,这样才能更加清晰的知道我们每天操作的命令都是在做什么。
Git 体系

Git 区域理解
- 远程仓库区:也就是我们代码最终提交的归宿,没啥好说的。
- 远端分支本地副本:这个其实主要储存了远程仓库各分支数据在本地的一个副本,你可以打开你 Git 项目下的 .git 文件,里面有个 refs/remotes,这里就主要存的就是远程仓库的分支信息,一般你执行 push 或者 pull、fetch 都会往这里进行更新。
- 本地分支:这里就是我们经常会打交道的区域,你在执行 commit 之后,本质上就是提交到了这个区域,你可以查看你的 .git 目录下的 refs/heads 目录,里面存的就是我们本地的分支代码信息。
- 暂存区:这个区域就是我们每次执行 git add 之后会存到的区域,用来与本地仓库之间做一个缓存,同时也是 Git 底层设计上来说也算是比较重要的一个区域,它能帮助 Git 在做 diff 的时候提高查找性能。
- 工作区:这个一般就是我们写代码的地方,比如你的 vscode 打开的项目,你可以进行代码编辑的地方。
stash
除此之外,还有一个特殊的区域,那就是本地的 git 储存区,它是用来干嘛的呢?一般来说你可能在某些场景下会用到它,我们有的时候本地改了代码,但是突然有个人过来问你另一个分支的问题,同时这个时候你在实现某个功能,实现一半,又不想提交到 Git 仓库中,那么你就可以考虑使用 git stash save “临时存一下”,这个时候它就会帮你存到这个储存区,你去其他分支做完事情回来,再 git stash pop就好了。
但笔者还是不是很建议使用这个功能,因为哪天你切走了再切回来,忘记了这个存储,又写了点其他的,这个时候你到时候被坑一把就哭吧。当然了,这个功能还是很有用的,但是的确需要细心点用。
Git 简单工作流理解
日常工作中,我们可能在 Git 使用上频繁交互的流程大致会是这样的(不同规范下会有一些区别,但是大差不大):
- 来了一个新需求,我们会从 master checkout 一个新的 feature 分支出来进行开发。
- 开发完某个功能点,我们会执行 git add 将代码提交到暂存区。
- 执行 git commit 将代码提交到本地仓库
- 执行 git push 将代码提交到远端分支
- 当我们开发完所有需求之后,可能会设立一个专门的测试分支比如名叫 dev 的分支,那么我们就把代码合并到这个测试分支上,发布测试环境进行测试。
- 测试完毕之后,我们就需要合代码了,这个时候,我们可以发起一个 merge request,将我们的代码走 CR 流程合并到 master 分支。
- 在提交 MR 的过程中,我们一般需要先自己预先将 master 分支的代码合并到当前需要被合并的分支,提交并解决冲突。
以上流程大致概括了一般常规的 Git flow 流程,不同的公司可能会设计自己的规范,这里就不过多指示了。
命令概览
- git stash
- git clone
- git init
- git remote
- git branch
- git checkout
- git add
- git commit
- git rm
- git push
- git pull
- git fetch
- git merge
- git log
- git reset
- git reflog
- git revert
- git cherry-pick
- git tag
- git rebase
乍一看,眼花缭乱,当场决定放弃,还是用可视化工具吧。莫慌,且让笔者为你娓娓道来。
命令解析
一般来说,我们本地如果想要使用 Git 管理一些资源文件,首先我们需要有一个仓库才行。常用的方式莫过于,第一去 Gitlab / Github 先创建一个仓库,然后再拉到本地,那这个时候我们就可以用到我们的 clone 命令了。
git stash(临时插进来快速介绍一下)
上面也有初步介绍这个命令的用法,就是用来临时存一下不想被提交的代码变更的,常用命令如下:
- git stash save ‘xxx’: 储存变更
- git stash list: 查看储存区所有提交列表
- git stash pop: 弹出并应用最近的一次储存区的代码提交
- git stash drop stash@{n}: 删除某次储存记录
- git stash clear: 清楚所有 stash 信息
它的数据将被存在你仓库 .git 文件下的 refs/stash 里。
git clone
最基础也是最常用的用法莫过于直接使用1
git clone xxx.git
这样就能轻松把一个仓库代码拉到本地了,但仅仅知道这一点似乎还不太够。一般我们直接 clone 下来不带参数的话,它会默认停留在 master 分支,有的时候我们依旧需要一些其他诉求,比如怎么拉到本地之后自动切到指定分支呢?1
git clone xxx.git -b branch1
有了仓库之后,我们总不能一直在 master 分支搞事吧,一般是不是都需要开个新分支改代码,再最后完事了再合到 master,那就需要用到下面介绍 git branch 命令了,不过呢,在讲到具体的分支操作之前呢,笔者还是要先补一下有关于本地仓库的初始化的流程。
git init
除了我们从远端建仓库,有的时候我们自己本地也是可以自己初始化一个 Git 仓库来操作的,这个时候我们就直接使用 git init 就能轻松为当前目录创建一个 git 仓库,也就能开始对当前目录的改动纳入版本管理库了。
不过本地 init 的仓库没法和远端进行交互,所以我们还是需要去 github/gitlab 创建一个远端仓库,然后关联一下,也就是 git remote 命令了。
git remote
用于和远程仓库进行关系绑定处理等等操作。
1 | git remote add: 添加一个远程版本库关联 |
比如我们本地有个初始化好的仓库,同时还有一个创建好的远程空仓库,那么我们就可以执行一下操作让他们关联起来:1
2git remote add origin xxx.git先添加到本地仓库
git push -u origin master:表示把当前仓库的 master 分支和远端仓库的 master 分支关联起来,后面我们执行 push 或者 pull 都可以非常方便的进行操作了。
git branch
在拿到一个项目之后,你首先还是应该看一下当前仓库现在有哪些分支,不要待会创建新分支发现名字重复之类的问题,那这个时候我们就可以使用 git branch 来查看一下相关的分支了。
1 | git branch:查看本地所有分支信息 |
一般来说如果分支太多的话,还是建议使用可视化工具来查看分支信息,比如 vscode 或者 source tree 等软件等等。
当然 IDEA 也是可以的。
git checkout
如果我们想以当前分支为基准,创建一个新的分支并切换过去,可以使用如下命令。
创建并切换到指定新分支:git checkout -b branch1
git add
我们在某个分支更改了代码之后,想要把它提交一下,那么你第一步要做的就是,执行 git add
- git add [file1] [file2]: 添加一个或多个文件到暂存区
一般我们平时在使用的时候,用的比较多的应该还是:
- git add .:把当前目录下得所有文件改动都添加到暂存区
- git add -A:把当前仓库内所有文件改动都添加到暂存区
对笔者来说,用的最多的还是这个 git add -A 命令,因为大多数情况,我们都应该把所有变更都加到暂存区里,如果没有,那大概率是忘了。
git commit
文件添加到暂存区之后,我们就可以执行下一步操作了。
- git commit [file1] … -m [message]:将暂存区的内容提交到本地 git 版本仓库中
-m 表示的是当前提交的信息
-a 对于已经被纳入 git 管理的文件(该文件你之前提交过 commit),那么这个命令就相当于帮你执行了上述 git add -A,你就不用再 add 一下了;对于未被 git 管理过的(也就是新增的文件),那么还是需要你先执行一下 git add -A,才能正确被 commit 到本地 git 库。
通常情况下,我们用的比较多得应该是 git commit -m ‘feat: do something’,设置当前提交的信息。当然,如果你没有强诉求需要 git add 和 git commit 一定要分开,那你大可选择 git commit -am,方便又快捷。
git rm
这个其实也挺有用的,比如我们项目中有个文件叫 .env,这个文件是一个私有的,不能被提交到远程的,但是我们不小心提交到了本地仓库中,这个时候我们把这个文件添加到 .gitignore 文件中,表示需要被 git 忽略提交,但是由于我们已经提交到本地仓库了,所以如果不先从 git 仓库删除是没用的。
如果直接右键删除,那么这个文件的记录还是会被保存到远端仓库,别人还是能看得到你这个信息,所以我们需要先从 git 仓库中删掉这个文件才行。
git rm .env:执行完这个命令就表示 .env 文件从 git 仓库中删除了,配合 .gitignore 就能保证以后所有的 .env 文件变更都不用担心被提交到远程仓库。
git rm -r dist:如果我们要删除的是一个目录,那么加上 -r 参数就好了。
git push
接下来我们想要把刚创建好得分支推送到远端,一般来说我们可能会需要用到 git push,但我们这是个新分支,根本没和远端仓库建立任何联系,那么我们就需要加点参数,让他们关联上:
- 推送分支并建立关联关系:git push –set-upstream origin branch1
完事之后我们可以再去远程仓库看一眼就会发现我们创建的新分支已经推上去了。接下来可能会有小伙伴要问了,那如果远端仓库已经有了这个分支名咋整?
这里就分两种:
- 一种就是你本地的代码和远端代码没有冲突的情况下,并且你本地有新增提交,那么你可以仍然执行上述命令,这样就会直接将当前本地分支合远程分支关联上,同时把你的改动提交上去。
- 另一种就是本地分支和远端分支存在冲突,这个时候你执行上述命令就会出现提示冲突,那么接下来就需要你先把远端当前分支的代码拉下来,解决一下冲突了,就需要用到 git pull 命令了。
git pull
通常情况下,如果当前分支已经和远端分支建立了联系,那么我们想要合并一下远端分支,只需要执行 git pull 就好了,不用带其他参数,但如果和上面提到的 git push 时产生了冲突,还没有建立联系的时候,我们就需要指定需要拉取哪个分支的代码下来进行合并了。
- 拉取指定远端分支合并到本地当前分支:git pull origin branch1
这里的 origin 是我们对远端仓库的命名,想改也是可以的,不过一般都是用的 origin。
回到上面提到的冲突问题,我们可以直接使用 git pull 然后指定合并当前本地分支想要建立联系的远程分支,然后本地解决一下冲突,然后提交一下改动,再执行 git push –set-upstream origin branch1 命令就大功告成了。
git fetch
了解完上面描述的 git pull,命令之后,其实这个命令也很好理解了,特定时候,可能我们只是想把远端仓库对应分支的变更拉到本地而已,并不想自动合并到我的工作区(你当前正在进行代码变更的工作区),等晚些时候我写完了某部分的代码之后再考虑合并,那么你就可以先使用 git fetch。
fetch 完毕之后,我提交了自己当前工作去的变更到本地仓库,然后想合并一下远端分支的更改,这个时候执行一下 git merge origin/[当前分支名](默认一般是用 origin 表示远端的分支前缀)即可。
git merge
合并指定分支代码到当前分支。一般来说,我们用的比较多的场景可能是,远端仓库 master 分支有变更了,同时这个时候我们准备提 MR 了,那么就需要先合一下 master 的代码,有冲突就解决下冲突,那这个时候我们可以做以下操作:
- 切到 master 分支,git pull 拉一下最新代码
- 切回开发分支,执行 git merge master 合并一下 master 代码
同理,上面介绍的 git merge origin/xxx 也是一样的用法。
git log
顾名思义,就是日志的意思,执行这个命令之后,我们能看到当前分支的提交记录信息,比如 commitId 和提交的时间描述等等,大概长下面这样:
1 | commit e55c4d273141edff401cbc6642fe21e14681c258 (HEAD -> branch1, origin/branch1) |
这个时候可能有读者会问了,这个都用来干啥的,简单的用法呢就是看看有谁提交了啥,还有更重要的用法呢就是进行代码版本的回滚,或者其他有意思的操作,且听笔者为你微微道来。
git reset
git reset [–soft | –mixed | –hard] [HEAD]
关于 HEAD:
- HEAD 表示当前版本
- HEAD^ 上一个版本
- HEAD^^ 上上一个版本
- HEAD^^^ 上上上一个版本
- HEAD~n 回撤 n 个版本,这种也是更加方便的
参数解析
以下解析均基于后接参数为 HEAD^,也就是git reset HEAD^。
- –soft: 重置你最新一次提交版本,不会修改你的暂存区和工作区。
- –mixed: 默认参数,用于重置暂存区的文件与上一次的提交(commit)保持一致,工作区文件内容保持不变。
- –hard: 重置所有提交到上一个版本,并且修改你的工作区,会彻底回到上一个提交版本,在代码中看不到当前提交的代码,也就是你的工作区改动也被干掉了。
说了半天似乎不是很好理解,我们举个栗子理解下:
比如:
- 我改动了我的 README 文件,在我们的工作区就产生了一次改动,但是这个时候还没有提交到暂存区,在 vscode 里会显示为工作区修改的标记
- 接着我们执行 git add,这个时候你查看暂存区,会发现这次改动被提交进去了,同时被 vscode 标记为已被提交至暂存区
- 然后再执行 git commit,这个时候就完成了一次提交
接下来我们想撤回这次提交,以上三种参数所体现的表现会是这样的:
- –soft:我们对 README 的更改状态现在变成已被提交至暂存区,也就是上面 2 的步骤。
- –mixed: 我们对 README 的更改变成还未被提交至暂存区,也就是上面 1 的步骤。
- –hard:我们对 README 的所有更改全没了,git log 中也找不到我们对 README 刚刚那次修改的痕迹。
默认情况下我们不加参数,就是 –mixed,也就是重置暂存区的文件到上一次提交的版本,文件内容不动。一般会在什么时候用到呢?
场景一(撤销 git add)
可能大部分情况下,比如 vscode 其实大家更习惯于使用可视化的撤销能力,但是呢,这里我们其实也可以稍微了解下这其中的奥秘,其实也很简单:
- 方式一:git reset
- 方式二:git reset HEAD
其实一二都是一样,如果 reset 后面不跟东西就是默认 HEAD。
场景二 (撤销 git commit)
当你某个改动提交到本地仓库之后,也就是 commit 之后,这个时候你想撤回来,再改点其他的,那么就可以直接使用 git reset HEAD^。这个时候你会惊奇的发现,你上一版的代码改动,全部变成了未被提交到暂存区的状态,这个时候你再改改代码,然后再提交到暂存区,然后一起再 commit 就可满足你的需求了。
除了这种基础用法,我们还可以配合其他命令操作一下。
场景三
某一天你老板跟你说,昨天新加的功能不要了,给我切回之前的版本看看效果,那么这个时候,你可能就需要将工作区的代码回滚到上一个 commit 版本了,操作也十分简单:
- git log 查看上一个 commit 记录,并复制 commitId
- git reset –hard commitId 直接回滚。
场景四
如果某一个你开发需求正开心呢,突然发现,自己以前改的某个东西怎么不见了,你想起来好像是某次合并,没注意被其他提交冲掉了,你心一想,完了,写了那么多,怎么办?很简单,回到有这份代码的那个版本就好了(前提你提交过到本地仓库)。
假设我们有这么两个提交记录,我们需要下面那个 365 开头 commitId 的代码:
1 | commit e62b559633387ab3a5324ead416f09bf347d8e4a (HEAD -> master) |
- 抢救第一步 git log 找到有你这个代码的那个 commitId(也就是 36577ea21d79350845f104eee8ae3e740f19e038)
- 抢救第二步 git reset –hard commitId
- 第三步:Ctrl + c 你的目标代码
这个时候你想把复制好的代码写回去,该怎么办呢,你可能会再 git log 看一下我们 reset 之前的 commitId,你会发现,完了,之前的 commitId 都没了,只有这个 365 了。
1 | commit 36577ea21d79350845f104eee8ae3e740f19e038 (origin/master, origin/HEAD) |
不要慌,请记住一句话,只要你不删你本地的 .git 仓库,你都能找回以前所有的提交。
git log 看不到的话,我们就可以祭出我们的绝招了:git reflog
1 | 36577ea (HEAD -> master, origin/master, origin/HEAD) HEAD@{0}: reset: moving to 36577ea21d79350845f104eee8ae3e740f19e038 |
这里我们可以看到两行记录,一个是我们执行 reset 到 365 的记录,另一条不知道是啥,不重要,我们想回到我们刚刚 reset 之前的状态也很简单,直接复制它上一次的变动也就是这个 e62b559,然后执行 git reset –hard e62b559,然后你会惊奇的发现,你之前的代码又回来了。
接下来把你以前版本的代码,再 Ctrl + v 放进来就完成了。
git reflog
介绍:用来查看你的所有操作记录。
既然 git log 看不到我之前 commitId 了,那么就回到 reset 之前的状态吧!
git revert
当然了,如果是针对 master 的操作,为了安全起见,一般还是建议使用 revert 命令,他也能实现和 reset 一样的效果,只不过区别来说,reset 是向后的,而 revert 是向前的,怎么理解呢?简单来说,把这个过程当做一次时光穿梭,reset 表示你犯了一个错,他会带你回到没有犯错之前,而 revert 会给你一个弥补方案,采用这个方案之后让你得到的结果和没犯错之前一样。
举个栗子:
假设你改了 README 的描述,新增了一行文字,提交上去了,过一会你觉得这个写了有问题,想要撤销一下,但是又不想之前那个提交消失在当前历史当中,那么你就可以选择使用 git revert [commitId],那么它就会产生一次新的提交,提交的内容就是帮你删掉你上面新增的内容,相当于是一个互补的操作。
1 | PS D:\Code\other\git-practice> git revert 3b18a20ad39eea5264b52f0878efcb4f836931ce |
这个时候,它会提示你可以把新的改动 push 上去了。
其实你如果在 gitlab 进行 mr 之后,想要回滚这个 mr,一般它会给你一个 revert 的按钮选项,让你进行更安全的回滚操作。
git cherry-pick
其实对于我们工作中大部分场景下应该用不到这个功能,但是呢有的时候这个命令又能挽救你于水火之间,那就是当某个倒霉蛋忘记切分支,然后在 master 分支上改了代码,并且提交到了本地仓库中,这个时候使用git cherry-pick简直就是神器了。
- git cherry-pick:将执行分支的指定提交合并到当前分支。
一听介绍就来精神了,雀氏有点东西,比如我在 master 分支提交了某个需求的代码,同时还没提交到远程分支,那么你就可以先 git log查看一下当前的提交,找到 master 分支正常提交之后的所有 commitId,然后复制出来,然后再切到你建好的开发分支,接着执行 git cherry-pick master commitId1 commitId2 commitId4。
完事之后记得清理一下作案现场,把你的 master 分支代码恢复到正常的提交上去。
git tag
顾名思义,也就是打标签的意思。一般可能会在你发布了某个版本,需要给当前版本打个标签,你可以翻阅 vite 的官方 git 仓库,查看它的 tag 信息,它这里就标注了各个版本发布时候的 tag 标签。
它有两种标签形式,一种是轻量标签,另一种是附注标签。
轻量标签
- 创建方式:git tag v1.0.0
它有点像是对某个提交的引用,从表现上来看,它又有点像基于当前分支提交给你创建了一个不可变的分支,它是支持你直接 checkout 到这个分支上去,但是它和普通分支还是有着本质的区别的,如果你切换到了这个 tag “分支”,你去修改代码同时产生了一次提交,亦或者是 reset 版本,这对于该 tag 本身不会有任何影响,而是为你生成了一个独立的提交,但是却在你的分支历史中是找不到的,你只能通过 commitId 来切换到本次提交,看图:
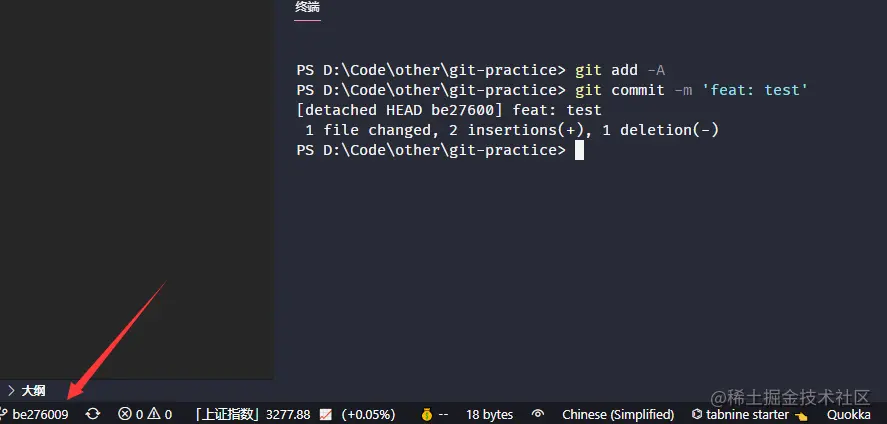
那如果你从其他分支通过 commitId 切换到这个改动上,它会提示你以下内容:
1 | Note: switching to 'be276009'. |
大致意思就是你可以选择丢弃或者保留当前更改,如果需要保留的话直接使用下面的 git switch 命令创建一个新分支即可。
附注标签
- 创建方式:git tag -a v1.0.1 -m “发布正式版 1.0.1”
引用官方文档的描述:
而附注标签是存储在 Git 数据库中的一个完整对象, 它们是可以被校验的,其中包含打标签者的名字、电子邮件地址、日期时间, 此外还有一个标签信息,并且可以使用 GNU Privacy Guard (GPG)签名并验证。
从概念上看,轻量标签更像是一个临时的标签,而附注标签更加正式一点,能够保留更多的信息。它创建的方式和轻量标签区别主要是 -a 和 -m 参数,如果你的 -m 参数不传,那么编辑器会让你手动填写。
对比标签信息
打完标签之后,我们可以使用 git show 命令来看看这两种标签最终体现的信息有哪些。
轻量标签
1 | commit dcbd335be87f51eaa0cc1852400e64e9f46e84d8 (HEAD -> test-branch1, tag: v1.0.2, tag: v1.0.1) |
附注标签
1 | tag v1.0.1 |
从信息丰富度上来说,附注标签能保留的信息会更多。
推送标签
- git push origin tagName
1 | $> git push origin v1.0.1 |
当然,附注标签和轻量标签都是可以被推送到远端的。
其他命令
- 查看标签:git tag
- 筛选标签:git tag -l v1.0.1
- 删除标签:git tag -d v1.0.1
删除远程标签:git push origin –delete v1.0.2
另一种删除远程方式(表示将“:”前面空值替换到远程,也不失为一种方式):
git push origin :refs/tags/v1.0.1
git rebase
使用 Git 已经好几年了,却始终只是熟悉一些常用的操作。对于 Git Rebase 却很少用到,直到这一次,不得不用。
一、起因
上线构建的过程中扫了一眼代码变更,突然发现,commit 提交竟然多达 62 次。我们来看看都提交了什么东西:

这里我们先不说 git 提交规范,就单纯这么多次无用的 commit 就很让人不舒服。可能很多人觉得无所谓,无非是多了一些提交纪录。
然而,并非如此,你可能听过破窗效应,编程也是如此!
二、导致问题
不利于代码 review
设想一下,你要做 code review ,结果一个很小的功能,提交了 60 多次,会不会有一些崩溃?会造成分支污染
你的项目充满了无用的 commit 纪录,如果有一天线上出现了紧急问题,你需要回滚代码,却发现海量的 commit 需要一条条来看。
遵循项目规范才能提高团队协作效率,而不是随心所欲。
三、Rebase 场景一:如何合并多次提交纪录?
基于上面所说问题,我们不难想到:每一次功能开发, 对多个 commit 进行合并处理。
这时候就需要用到 git rebase 了。这个命令没有太难,不常用可能源于不熟悉,所以我们来通过示例学习一下。
1.我们来合并最近的 4 次提交纪录,执行:
1 | git rebase -i HEAD~4 |
2.这时候,会自动进入 vi 编辑模式:
1 | s cacc52da add: qrcode |
有几个命令需要注意一下:
- p, pick = use commit
- r, reword = use commit, but edit the commit message
- e, edit = use commit, but stop for amending
- s, squash = use commit, but meld into previous commit
- f, fixup = like “squash”, but discard this commit’s log message
- x, exec = run command (the rest of the line) using shell
- d, drop = remove commit
按照如上命令来修改你的提交纪录:
1 | s cacc52da add: qrcode |
3.如果保存的时候,你碰到了这个错误:
1 | error: cannot 'squash' without a previous commit |
注意不要合并先前提交的东西,也就是已经提交远程分支的纪录。
4.如果你异常退出了 vi 窗口,不要紧张:
1 | git rebase --edit-todo |
这时候会一直处在这个编辑的模式里,我们可以回去继续编辑,修改完保存一下:
1 | git rebase --continue |
5.查看结果
1 | git log |
三次提交合并成了一次,减少了无用的提交信息。

四、Rebase 场景二:分支合并
1.我们先从 master 分支切出一个 dev 分支,进行开发:
1 | git:(master) git checkout -b feature1 |
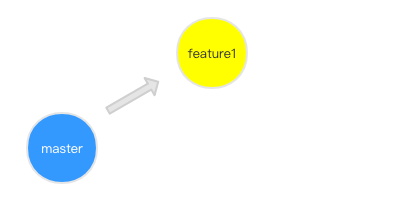
2.这时候,你的同事完成了一次 hotfix,并合并入了 master 分支,此时 master已经领先于你的feature1 分支了:
3.恰巧,我们想要同步 master 分支的改动,首先想到了 merge,执行:
1 | git:(feature1) git merge master |
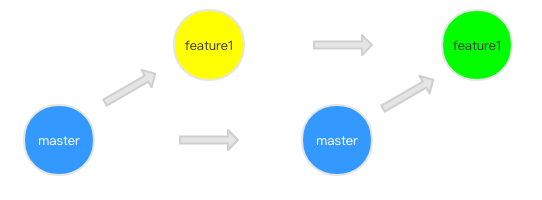
图中绿色的点就是我们合并之后的结果,执行:
1 | git:(feature1) git log |
就会在记录里发现一些 merge 的信息,但是我们觉得这样污染了 commit 记录,想要保持一份干净的 commit,怎么办呢?这时候,git rebase 就派上用场了。
4.让我们来试试 git rebase ,先回退到同事 hotfix 后合并 master 的步骤:
5.使用 rebase 后来看看结果:
1 | git:(feature1) git rebase master |
这里补充一点:rebase 做了什么操作呢?
首先,git 会把 feature1 分支里面的每个 commit 取消掉;
其次,把上面的操作临时保存成 patch 文件,存在 .git/rebase 目录下;
然后,把 feature1 分支更新到最新的 master 分支;
最后,把上面保存的 patch 文件应用到 feature1 分支上;
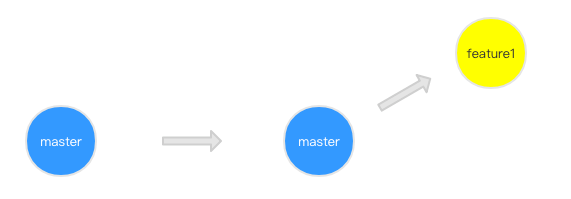
从 commit 记录我们可以看出来,feature1 分支是基于 hotfix 合并后的 master ,自然而然的成为了最领先的分支,而且没有 merge 的 commit 记录,是不是感觉很舒服了。
6.在 rebase 的过程中,也许会出现冲突 conflict。在这种情况,git 会停止 rebase 并会让你去解决冲突。在解决完冲突后,用 git add 命令去更新这些内容。
注意,你无需执行 git-commit,只要执行 continue
1 | git rebase --continue |
这样 git 会继续应用余下的 patch 补丁文件。
7.在任何时候,我们都可以用 –abort 参数来终止 rebase 的行动,并且分支会回到 rebase 开始前的状态。
1 | git rebase —abort |
五、更多 Rebase 的使用场景
git-rebase 存在的价值是:对一个分支做「变基」操作。
1.当我们在一个过时的分支上面开发的时候,执行 rebase 以此同步 master 分支最新变动;
2.假如我们要启动一个放置了很久的并行工作,现在有时间来继续这件事情,很显然这个分支已经落后了。这时候需要在最新的基准上面开始工作,所以 rebase 是最合适的选择。
六、为什么会是危险操作?
根据上文来看,git-rebase 很完美,解决了我们的两个问题:
1.合并 commit 记录,保持分支整洁;
2.相比 merge 来说会减少分支合并的记录;
如果你提交了代码到远程,提交前是这样的:
提交后远程分支变成了这样: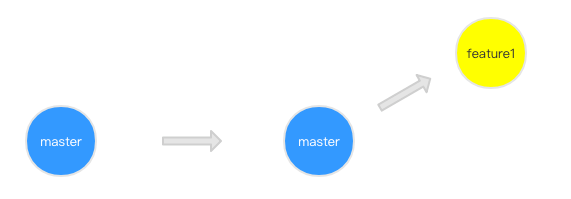
而此时你的同事也在 feature1 上开发,他的分支依然还是:
那么当他 pull 远程 master 的时候,就会有丢失提交纪录。这就是为什么我们经常听到有人说 git rebase 是一个危险命令,因为它改变了历史,我们应该谨慎使用。
除非你可以肯定该 feature1 分支只有你自己使用,否则请谨慎操作。
结论:只要你的分支上需要 rebase 的所有 commits 历史还没有被 push 过,就可以安全地使用 git-rebase来操作。

